
Au départ une simple panne de l’accès à distance du serveur : impossible de travailler à distance, pas de licence disponible. Voilà le point de départ d’un problème sur la sauvegarde.
J’ai volontairement simplifié des concepts de sécurité intégrés au serveur Windows et aux techniques de sauvegarde, ce qui devrait faire hurler certains confrères.
Les 2 méthodes de sauvegardes actuelles

A l’époque des sauvegardes sur bande (oui cela existe toujours), on recopie les fichiers sur la bande dans leur intégralité. Chaque fichier est lu puis recopié sur le support de la sauvegarde. On alterne sauvegarde complète et sauvegarde différentielle (uniquement les fichiers modifiés).
La recopie des fichiers sur un autre support : prend du temps (il faut transférer tous les fichiers modifiés), occupe plus de place, avec parfois des problèmes avec les fichiers PST (outlook) ou les fichiers ouverts.
La technique souvent utilisée aujourd’hui sauvegarde des blocs. Le contenu des données sur un disque dur est découpé en bloc, ou secteur. Les systèmes de sauvegarde permettent d’identifier les blocs modifiés. Pour simplifier, ce type de sauvegarde ne sauvegarde pas les fichiers, mais leur emplacement.
Le snapshot : photocopie du disque, rapide (copie uniquement des blocs du disque modifié), qui occupe peu de place, utilise la technologie VSS de Microsoft (obligatoire).
Le risque dans les sauvegardes de type Snapshot
Comme la sauvegarde snapshot correspond à une photocopie du disque dur, comme face à la photocopieuse si votre original est taché, votre photocopie est tachée.
Donc si vous avez une erreur disque dur, la sauvegarde va recopier l’erreur disque dur sur la sauvegarde. Ainsi lors de la récupération des données, vous avez une merveilleuse erreur disque.
Remonté dans le temps (RTO)
Vous avez un historique de sauvegarde, et ainsi vous pouvez par exemple remonter la sauvegarde existante avant l’erreur disque, 10 jours plus tôt.

Composant d’un serveur Windows
Lors de la mise en œuvre d’un serveur Windows dans l’entreprise, celui ci est décomposé en deux grandes partie :
- Un espace pour vos données
- Le service d’annuaire, Active Directory
Dans la partie des données vous allez stocker vos fichiers, les données de votre ERP, les informations de votre GPAO, etc.
L’Active Directory met en place un service d’annuaire des utilisateurs. Ce service permet par exemple d’ouvrir une session avec son login et son mot de passe sur tous les ordinateurs de l’entreprise (hors restriction spécifique mise en œuvre).
Pour sécurisé les échanges entre le serveur et le poste utilisateur ce service crée des clés de cryptage qu’il change à chaque connexion utilisateur et chaque jour. Pour que la sécurité soit efficace l’écart de temps entre le serveur et les postes de travail doit être réduit à moins de 24h (oui, je simplifie).
En cas de panne sur le serveur Active Directory
Dans mon cas, il s’agit du serveur principal Active Directory qui est endommagé. Donc si vous avez besoin de remonter dans le temps pour une durée supérieur à 24 heures, vous devez soit :
- récupérer la sauvegarde des postes de travail pour être aligné sur les clés d’authentification
- Sortir et réintégrer les postes dans l’Active Directory, ce qui implique de perdre les paramètres utilisateurs, les favoris de navigation, les fichiers sur le bureau, etc. Ce que j’ai du faire au final.
La redondance Active Directory c’est bien, monitorée c’est mieux

Pour le serveur AD (Active Directory) il est possible de créer des serveurs « secondaires » qui vont contenir une copie des informations de connexions des postes et des utilisateurs.
Pour tous ceux que cela chatouille de voir « secondaire », et qui pense que je suis resté sur Windows Server NT4 BDC, je réponds que chaque rôle FSMO ne peut être hébergé par un seul serveur à la fois.
Malheureusement la synchronisation s’est arrêtée 10 jours plus tôt, suite à une erreur de réplication. Donc les serveurs secondaires c’est très bien, à condition de mettre en place un système de monitoring et d’analyse des évènements (trace des activités opérationnelles et en erreurs), et ceux malheureusement quelque soit la taille de votre entreprise.
Le hardware s’en mêle
Le système de sécurité des disques durs RAID permet la recopie des informations en temps réel, pratiquement, sur un autre disque. Aussi en cas de panne d’un disque dur vous pouvez continuer de travailler. Et puis vous pouvez compter sur vos sauvegardes en cas de crash disque :
Et c’est à ce moment que votre extension de garantie 8 heures entre en action.
Vous contactez le support technique du constructeur, vous envoyer les éléments d’analyse de la panne pour que votre interlocuteur puisse prendre en charge celle-ci, suivant le constructeur prévoir entre 2 et 4 heures.
Ensuite il vous rappelle, et vous annonce que votre disque dur est bien en panne, et qu’il va demander un remplacement de celui-ci.
Chance, tout cela c’est passé dans l’après-midi, vous pensez recevoir le disque dur le lendemain. Le contrat du constructeur que vous avez souscrit a été rempli, il a pris en charge votre demande dans les 8 heures.
La crise du Covid19
Le lendemain, pas de disque, le surlendemain week-end. Le lundi vous recontactez avec votre numéro d’appel le support. C’est à ce moment-là que vous prenez conscience de la crise mondiale des composants : nous n’avons pas cette référence en stock, je vous rappelle pour faire un échange avec un disque compatible.
Finalement le disque arrive un mercredi, 7 jours plus tard, la reconstruction du RAID prendra 48 heures, mais la sécurité des disques est maintenant revenu, enfin presque
Encore des surprises
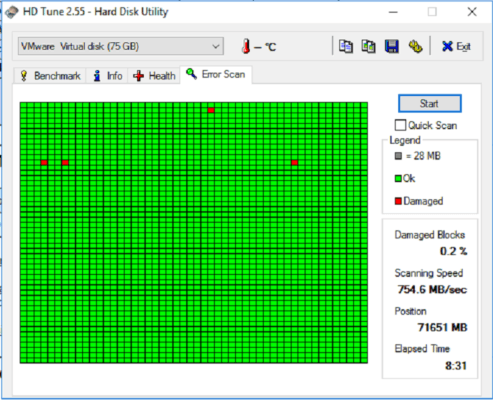
Les erreurs disques restent présentes sur les machines virtuelles.

Les 2 autres disques passent dans un état dégradé, mais ne sont pas pris en charge par le support du constructeur. Je pense que j’arriverais à les faire remplacer, mais cela va prendre du temps.
Cet état dégradé explique sans doute la présence encore d’erreurs secteurs sur les disques durs des machines virtuelles, ce qui bloque la sauvegarde en mode Snapshot.
Je trouve 3 disques durs a mettre en place dans le serveur, je créer une nouvelle espace de stockage sur le serveur, et je lance la copie des serveurs entre les 2 disques Raid. Je lance cela un vendredi après-midi, pour que lundi matin tous soient opérationnels.
Encore ratée, la copie des disques est impossible, car des erreurs disques bloquent celle-ci. Même le tout nouveau serveur AD que j’ai créé est en erreur. C’est sur ce serveur que j’ai reconnecter les postes sur une nouvelle Active Directory sans perdre les préférences utilisateurs.
Je tente une copie des fichiers de disque à disque via la commande ROBOCOPY pour transférer les fichiers entre 2 serveurs, idem des centaines d’erreurs qui rendent la copie non fiable.
Pas de problème, j’ai la sauvegarde des données via le système de copie de fichier que j’ai mis en place il y a quelques mois.
Sauvegarde fichier temps réel

Cette solution est géniale, sur le papier. Elle permet de réaliser une sauvegarde des fichiers sitôt que ceux-ci sont modifiés. Donc en cas de panne, le temps de perte de fichier est pratiquement nul. J’ai déjà testé la solution en situation réelle chez un autre client et chez moi.
Elle fonctionne parfaitement à une condition : que le serveur qui a fait la sauvegarde, soit le même que celui qui récupère les données. Et cela n’est pas mon cas, car le serveur existant et planté mais toujours en marche, car il héberge les licences logiciels, et reste serveur AD de l’ancien système.
Quand le serveur ne porte pas le même nom, la récupération se fait à la manière d’une copie des données : et dans ce cas toutes les versions de la structure de l’arborescence des fichiers sont récupérées. Comme une assistante avait pris le temps de créer un super classement des dossiers, elle se retrouve à devoir faire le tri entre les anciens et les nouveaux dossiers. Aussi il n’y a pas de perte de fichiers, mais trop de fichiers au final (beaucoup de doubles).
Une situation à risque qui a duré trop longtemps
Mon plus grand soucis a été pendant toute la période de permettre aux collaborateurs de continuer de travailler et d’avoir des sauvegardes de leur travail.

Ce fut au final une cascade de panne (5 au total) avec à chaque fois le risque de perdre de données :
- Panne RDP (accès à distance)
- Panne AD
- Panne sauvegarde Snapshot
- Panne synchronisation Active Directory
- Panne disques dur physiques
Le retour à une situation normale à une durée d’environ 2 mois et 5 demi-journées de coupure de service non consécutives. Les 2 systèmes de sauvegarde ont été remis en place, mais j’ai abandonné la sauvegarde en temps réel des fichiers, j’ai opté pour une sauvegarde toutes les 6 heures.
S’il avait fallu mettre en place une solution qui permet, de n’avoir aucune erreur aurait été un deuxième serveur physique répliqué. Mais cette solution n’est pas adaptée à la taille et au budget de l’entreprise.
Si vous connaissez ce panneau

Idem en informatique, une panne informatique peut en cacher une autre
Et pour vos sauvegardes, vous devez vous assurer avec votre DSI externalisé que vous avez mis en place les 2 systèmes de sauvegardes : Snapshot et Copie. Normalement une seule suffit, mais dans des cas complexes les 2 sont un atout.
Update Juin
Suite aux orages du mois de juin l’onduleur à rendu l’âme lui aussi. Le switch a suivi derrière.